作为当前人工智能发展的重要方向,预训练大模型已成为AI领域的技术新高地。
12月8日,鹏城实验室与百度联合发布双方共同研发的全球首个知识增强千亿大模型——鹏城-百度·文心(模型版本号:ERNIE 3.0 Titan)。
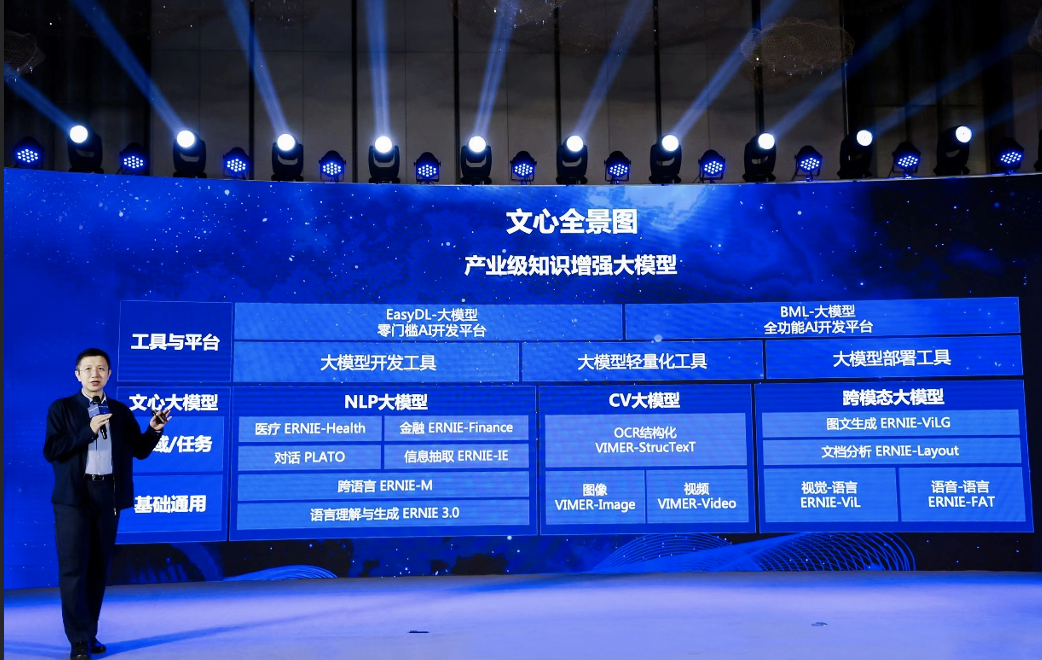
据悉,该模型参数规模达到2600亿,是目前全球最大中文单体模型,在60多项任务上取得最好效果。同时,百度产业级知识增强大模型“文心”全景图首次亮相,从技术自主创新和加速产业应用两方面,推动AI发展更进一步。
中国工程院院士、鹏城实验室主任高文表示,“预训练模型对整个科学的发展、社会的发展、创新的发展都是非常重要的工具。运用这个工具,可以帮助做很多人工智能的赋能,不局限于某个领域。”
百度首席技术官、深度学习技术及应用国家工程实验室主任王海峰介绍,百度知识增强大模型从大规模知识和海量数据中融合学习,效率更高、效果更好,具有良好的可解释性。
据了解,鹏城-百度·文心是“全球首个知识增强千亿大模型”,在机器阅读理解、文本分类、语义相似度计算等60多项任务取得最好效果,并在30余项小样本和零样本任务上刷新基准。
鹏城-百度·文心亮相的“背后”是鹏城实验室的算力系统“鹏城云脑Ⅱ”和飞桨深度学习平台的强强联手,解决了超大模型训练的多个技术难题,使鹏城-百度·文心训练效率大幅提升,模型效果更优。其中,“鹏城云脑Ⅱ”是国产自主的首个E级AI算力平台,曾在多个国际性能测试上获得冠军。飞桨是国内首个自主研发的深度学习开源开放平台,研制了端到端自适应分布式训练框架,实现多硬件支持,并行效率高达90%,有效支持鹏城-百度·文心千亿大模型高效、稳定地训练。
目前,百度文心通过百度飞桨平台陆续对外开源开放,并已大规模应用于百度搜索、信息流、智能音箱等互联网产品,同时通过百度智能云赋能工业、能源、金融、通信、媒体、教育等各行各业。在金融领域,基于百度文心实现了合同智能解析,能够在1分钟内完成对相关合同条款文本的解析识别,速度是之前的几十倍,大大提升了工作效率。
文/广州日报·新花城记者 文静
图/广州日报·新花城记者 文静
广州日报·新花城编辑 钱佳芸